

前言
本文的标题是反后门攻击,在进一步读下去之前,我们自然要先知道什么是后门学习。
后门攻击,一般指通过毒化训练集的方式在由该数据集训练出的模型上植入后门,关于后门攻击的文章,在安全客上也有很多了,大家可以去了解详情。
本文要介绍的反后门攻击,其面临的场景和后门学习是一样的—攻击者给了毒化数据集,但是却希望能够在这个数据集上训练得到一个没有后门的模型,因为是在毒化数据上训练出干净模型,所以我们将其称之为反后门攻击。这个工作来自于AI顶会NeurIPS 2021。
这个技术的提出是有一定意义的。我们可以把深度学习中的后门攻击类比于软件安全中的供应链攻击,毒化数据相当于被黑客攻破的编译器等上游资源,反后门学习的作用就是在毒化数据上训练得到正常模型,其意义完全可以类比于在被植入后门的Xcode上编译出无后门的App。
反后门学习
接着我们来形式化这个方案。
我们现在面对的场景是这样子的:攻击者已经生成了毒化样本,并对训练集进行投毒,而作为用户,我们拿到的是毒化后的数据集,我们的目标是在这个毒化数据集基础上训练处不带有后门的模型。
我们假设一个标准的分类任务的数据集为:
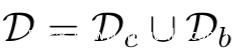
其中Dc表示原数据,也可以说是感觉数据,Db表示毒化数据。那么训练一个DNN模型就是通过最小化下面的经验误差就可以了:
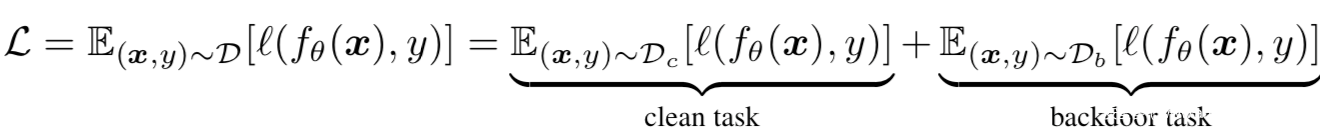
其中,l表示损失函数,比如常用的交叉熵损失。
从上面的公式中我们可以看到,整体的学习流程被分为了两部分,第一个是clean task,即在干净数据Dc上训练模型,第二个是backdoor task,即在毒化数据Db上训练模型。由于毒化样本通常与某个特定的目标类相关联,所以所有来自Db的数据可能都有着相同的标签。上面这个公式的分解非常清晰地表明了这种学习方式会同时学到两个任务,从而导致训练出的模型被嵌入后门。
为了防止模型学习到后门样本,我们可以最小化下面的经验误差来进行学习:
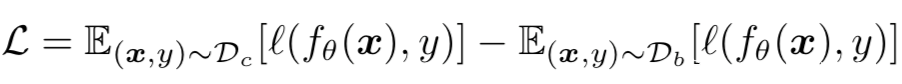
注意,上式中我们实际上是最大化了后门任务的训练。
这种方法虽然看起来很直观,但是我们作为用户实际上并不知道哪些数据来自Db。当然,我们可以先检测出Db,然后将它从训练集中分类出来即可。那么该怎么检测呢?
很明显,模型是通过数据训练出来的,那么用毒化数据训练出来的模型和干净数据训练出的模型的表现是不同的,甚至这种差异在模型训练期间应该就可以观察到。事实上也的确如此,研究人员应用多种后门攻击方案进行学习,得到了在干净数据和毒化数据上的损失情况,如下所示
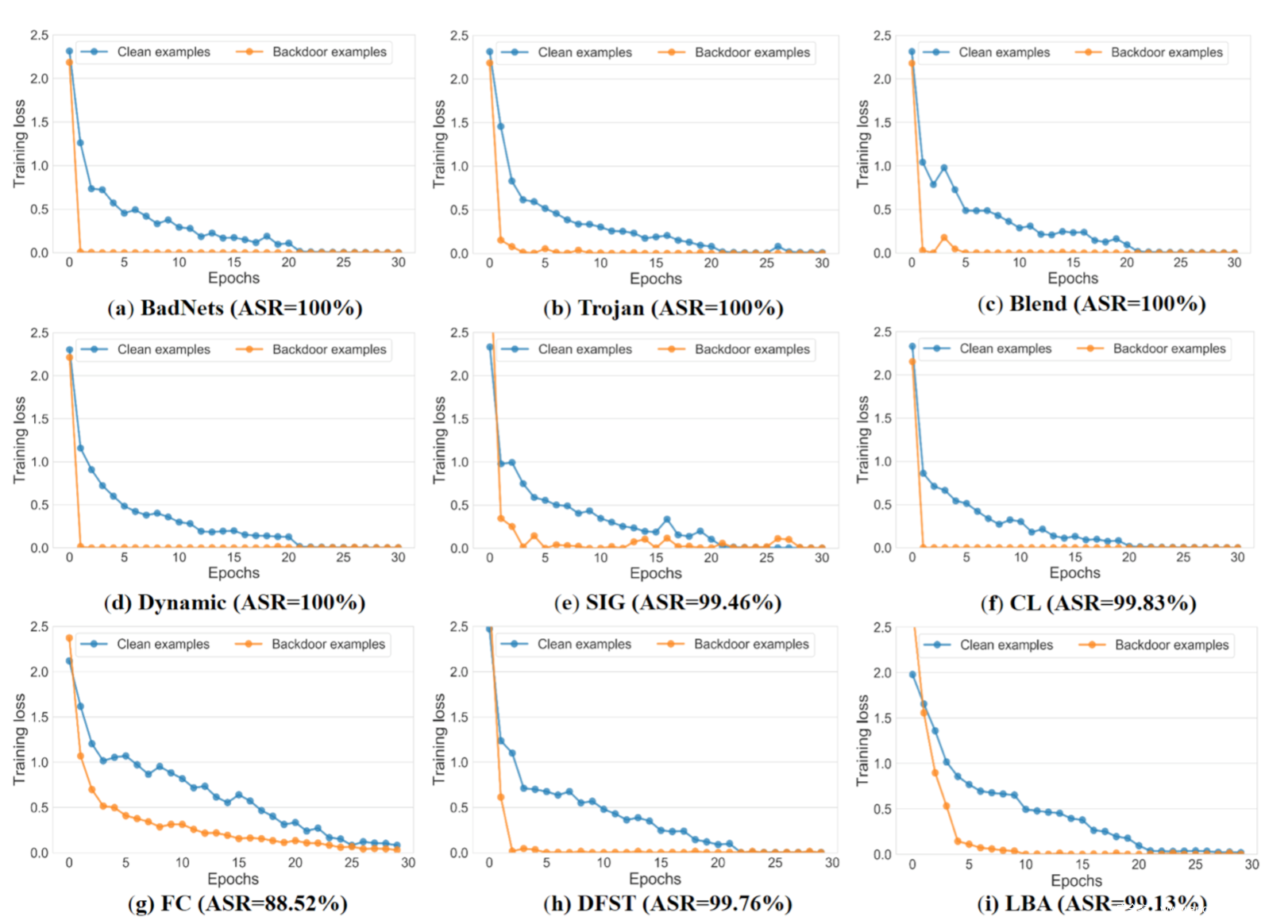
从图中可以看到,在这9种典型的后门攻击中,毒化样本上的训练损失在前几个epoch下降得要比干净样本快得多。
这一现象说明,训练后门任务比训练正常任务要容易得多,这背后的原因其实不难解释,因为后门攻击就是在触发器和目标标签之间增强了相关性,所以才能简化和加速触发器的注入。所以为了使得后门攻击成功,模型就要更容易学习带有触发器的毒化样本才行。
既然观察到了这个现象,我们就知道接下来该怎么做了。
首先假设训练epoch的总数为T,我们可以将整个训练过程分为两个阶段,即前期训练和后期训练。用Tte表示两个阶段的转折点,当平均训练损失开始稳定时我们选择此时的epoch作为Tte。然后我们在前期训练期间进行后门隔离,后期训练期间进行后门遗忘。这两个阶段的损失函数如下所示
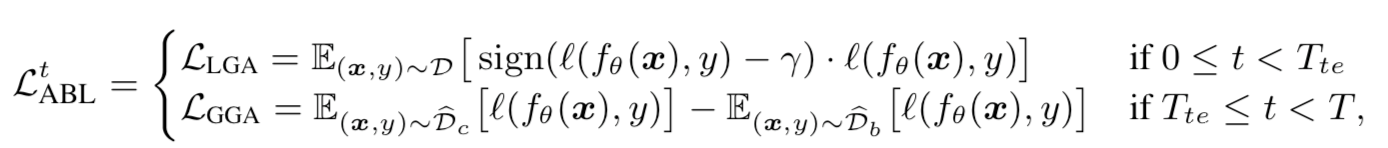
后门隔离
在前期训练阶段,我们应用局部梯度上升技术,使用上面公式中的损失函数LLGA将每个样本的损失限制在特定的阈值γ附近。梯度上升之所以被称为局部是因为最大化是围绕固定损失γ 进行的。换句话说,如果训练样本的损失低于 γ,将应用梯度上升以将其损失增加到 γ;否则,损失保持不变。这样子可以可以让毒化样本摆脱 γ 约束,因为它们的损失值下降得更快。这里的关键是选择合适的γ,过大的 γ 会影响模型学习原任务,而过小的 γ 可能不足以将原任务与后门任务分开。
在前期训练结束时,我们实际上已经将样本分为了两部分:具有最低损失的p%的数据会被认为是Db,剩下的是Dc。
当然了,这种方法不可能把全部的后门样本都检测并隔离出来,所以我们还需要在后期训练阶段应用后门遗忘。
隔离出的部分后门样本,当γ = 0时如下所示

此时还有一部分误报
γ = 0.5时如下所示

此时基本上没有误报的
后门遗忘
在这一阶段,模型已经开始学到后门了,所以现在的问题就是怎么在学习Dc中的没被检测出的后门样本的同时是用欧冠已经检测出的后门样本Db训练模型让其遗忘后门。
实现这个目标是有可能的,因为后门攻击有个显著的特点就是:触发器通常与一个特定的目标类别相关。所以可以上面公式中的LGGA来解决。
我们在Db上定义了全局梯度下降,注意这里和之前提到的局部梯度下降不同,这里并没有限制在固定的损失值附近。
实验分析及复现
分析
为了证实反后门学习确实有效,这里选了10种典型的后门攻击进行实现,分别是:
BadNets ,Trojan attack , Blend attack, Dynamic attack, Sinusoidal signal attack(SIG),Clean-label attack(CL), Feature collision (FC) , Deep Feature Space Trojan Attack (DFST), Latent Backdoor Attack (LBA) Composite Backdoor Attack (CBA)
同时和其他三种防御方案进行对标,实验数据如下
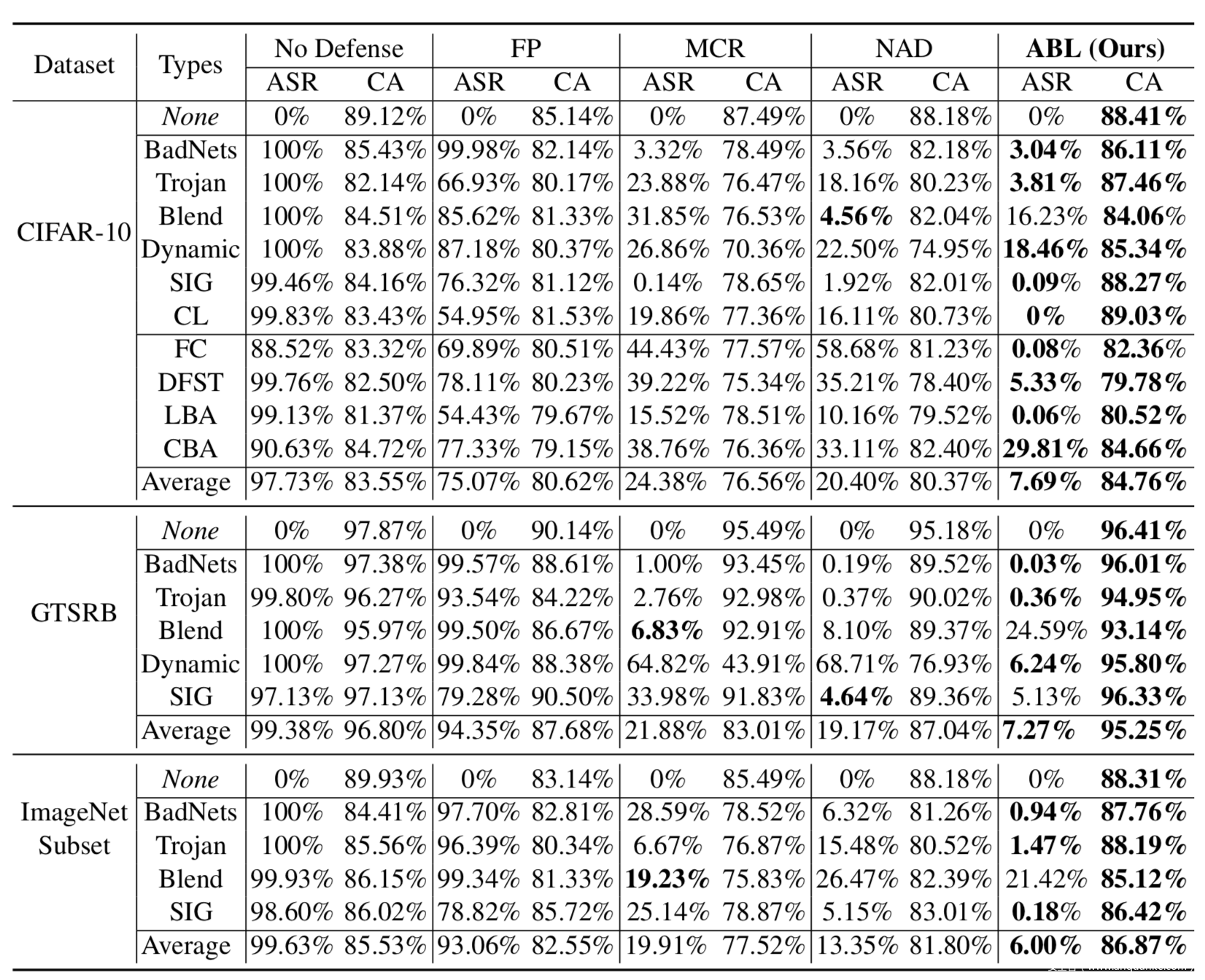
表中的ASR表示攻击成功率,CA表示原任务的准确率。黑体的数据是同等情况下表现最好的,可以看到反对抗学习在多数情况的表现都是最优的。
另外,我们之前提到过,隔离率的不同会影响到模型训练后的具体效果,通过实验也同样可以说明这一点,如下所示
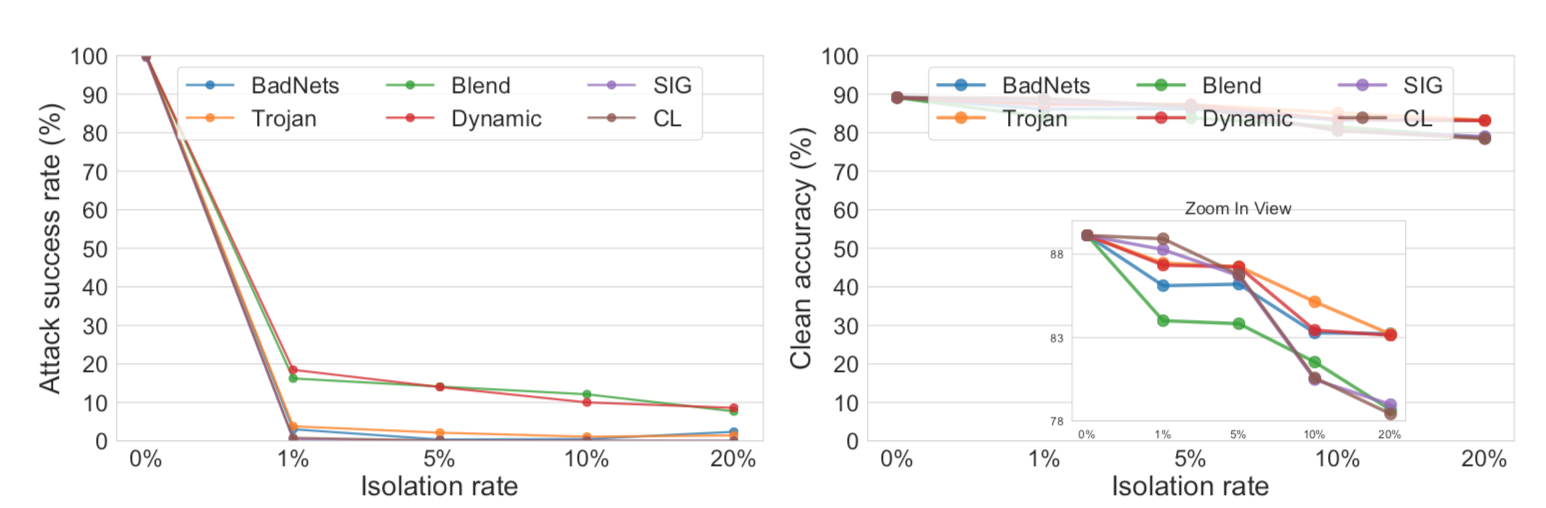
从图中可以看到,ASR的降低和CA之间是存在权衡的。比如一个较高的隔离率可以隔离更多的后门样本,更多的后门样本有助于后期的后门遗忘,所以可以更大幅度降低ASR,但是由于将更多的样本进行了遗忘,所以这也会导致CA的降低。
还有一点也需要研究,那就是转折点,即区分前期训练和后期训练的那个epoch,这个没有理论指导,只能通过实验去试,得到的数据如下

可以看到,当转折点选在第20个epoch时较好,越往后的话,该方案的表现越差。
该方案的第一步是要检测或者说隔离出后门样本,那么其他检测后门样本的方法是否可以替换到本方案基于LGA的部分呢?典型的检测样本的方案有AC和SSA,我们可以分别试试看。如下所示
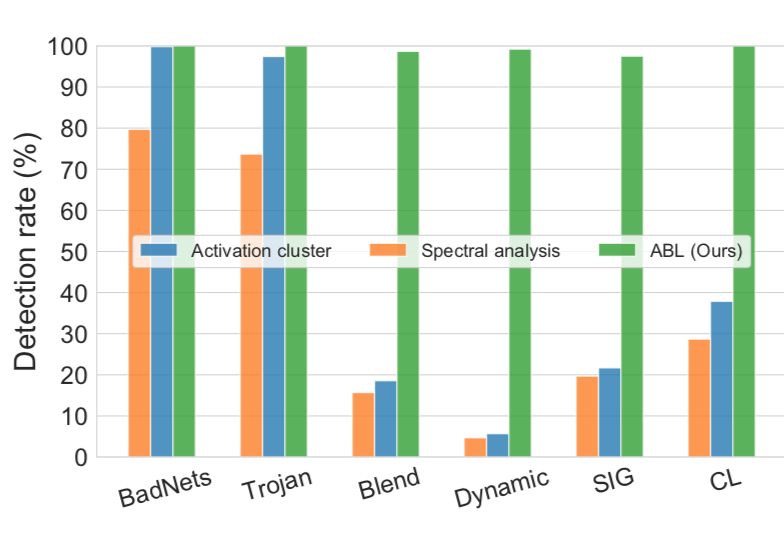
可以看到,这两类方案的检出率都不如本方案的,更具体地说,在BadNets和Trojan上三类方案表现得差不多,但是在后四类就差得远了,这其实也不难解释,因为后四类使用了复杂的触发器(Blend、Dynamic、SIG 和 CL)覆盖整个图像的攻击会导致AC或SSA混淆,从而使这些检测方法无效。
复现
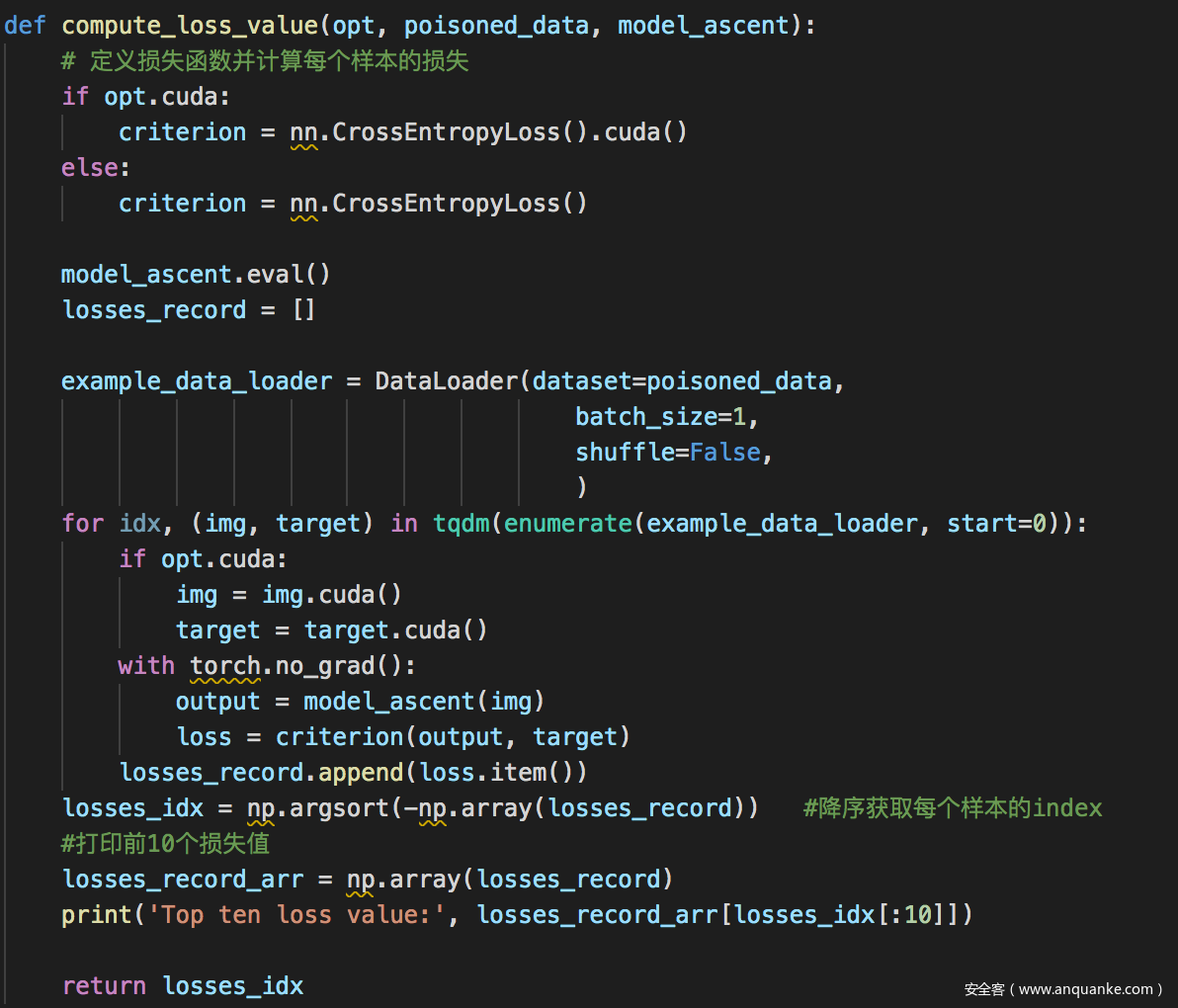
后门隔离-计算损失的代码
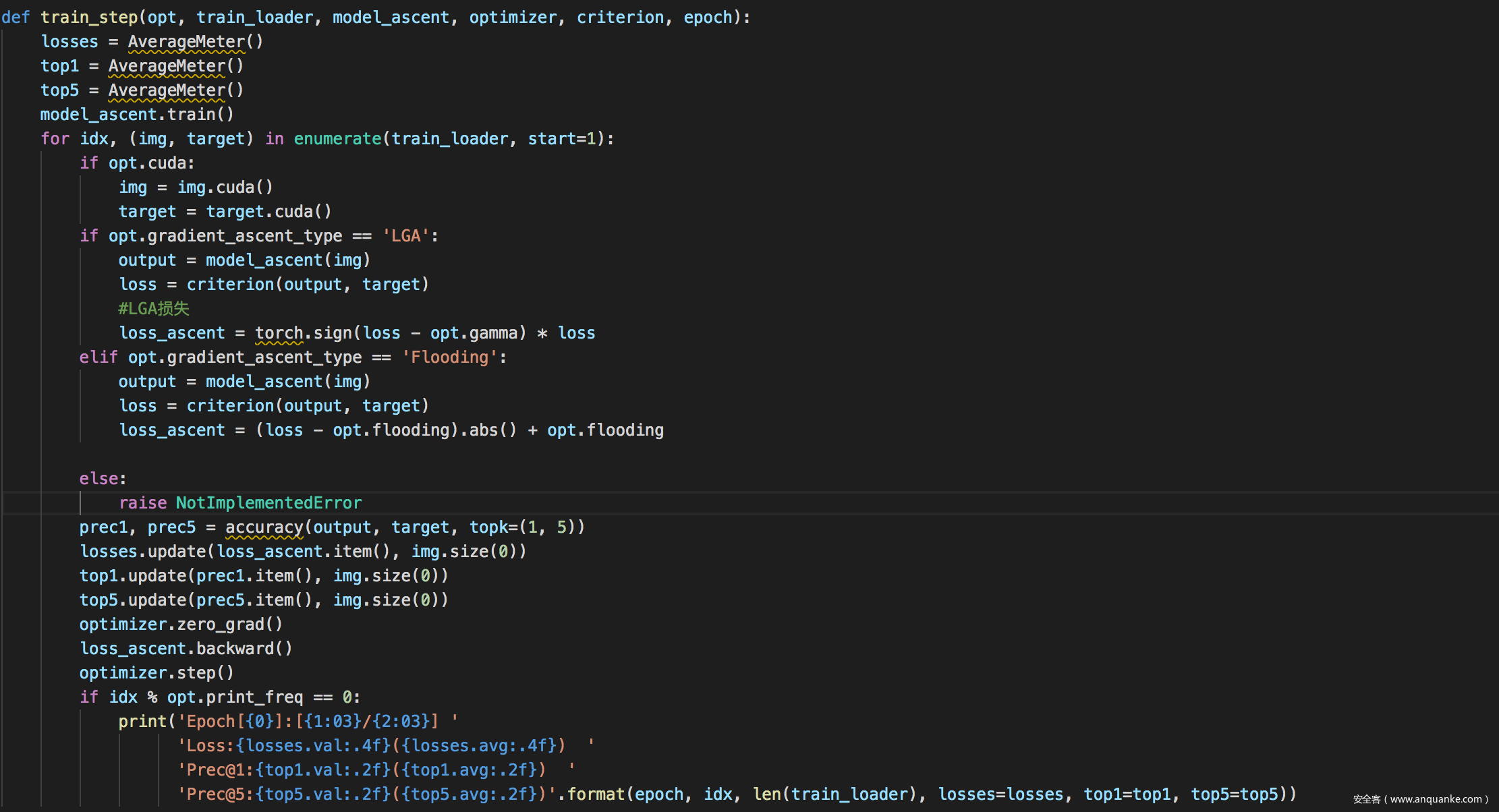
后门隔离-训练部分
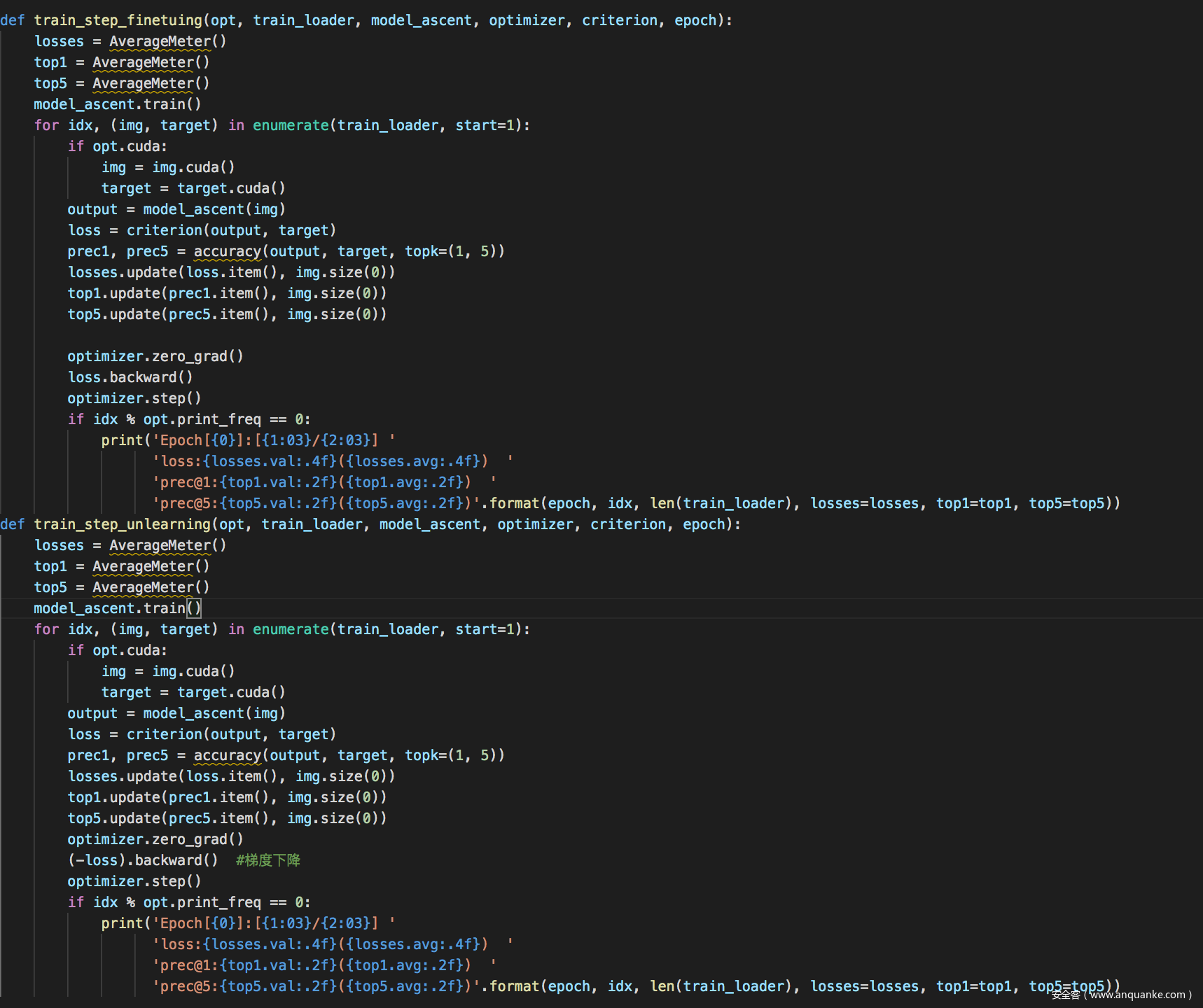
后门遗忘关键代码
使用后门遗忘的效果如下所示
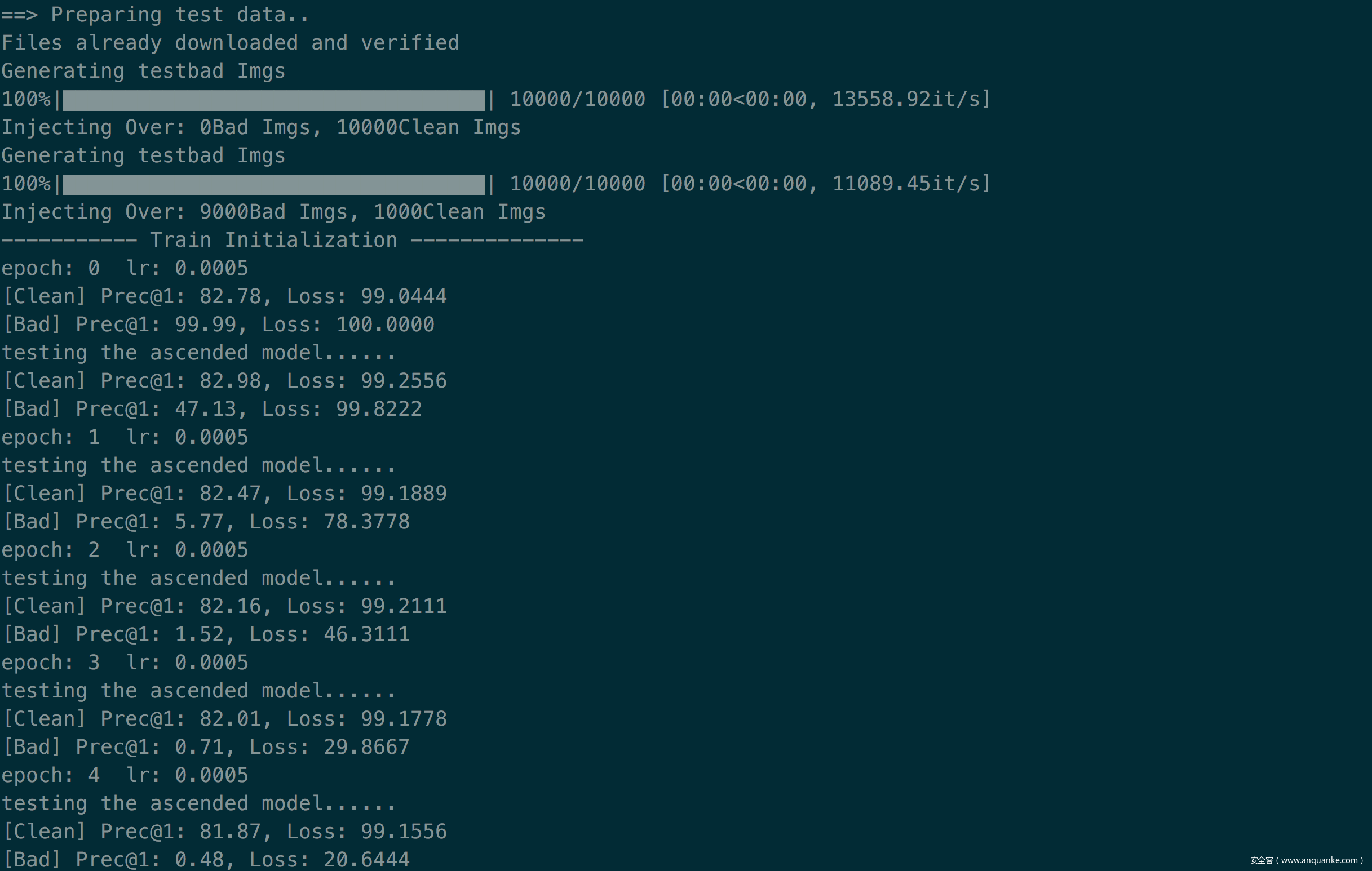
从图中可以看到,后门遗忘的效果就是原任务的acc基本保持不变的同事,后门任务的acc或者说攻击成功率却一直在下降,在图中是从99.99降到了0.48
总结
这个方案非常直观简洁,本质上是利用了后门攻击的两个特点:1.后门样本相比于原样本更容易被学习;2.带有触发器的后门样本与目标标签之间有很强的相关性。由此引出了所谓的反后门学习,其包括两个阶段,第一个阶段是在前期训练时使用局部梯度上升最大化两类样本之间的训练损失的差距,并以此为依据隔离毒化样本;第二个阶段就是使用全局梯度上升使用第一阶段的样本实现后门遗忘。
另外,由于方案的Insight实在是太凝练了,所以作者还花了大量篇幅做其他的实验辅助说明,把这个工作做得非常彻底,这也许能给要发论文的师傅们带来些启发。
参考
1.Anti-Backdoor Learning: Training Clean Models on Poisoned Data.
2.BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
转载请保留出处和原文链接:https://www.cnhackhy.com/157249.htm




