目录
1. sort_values
pandas中的sort_values()函数原理类似于SQL中的order by,可以将数据集依照某个字段中的数据进行排序,该函数即可根据指定列数据也可根据指定行的数据排序。
官方文档
## 参数
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
#### 参数说明
axis:{0 or ‘index', 1 or ‘columns'}, default 0,默认按照索引排序,即纵向排序,如果为1,则是横向排序
by:str or list of str;如果axis=0,那么by="列名";如果axis=1,那么by="行名";
ascending:布尔型,True则升序,可以是[True,False],即第一字段升序,第二个降序
inplace:布尔型,是否用排序后的数据框替换现有的数据框
kind:排序方法,{‘quicksort', ‘mergesort', ‘heapsort'}, default ‘quicksort'。似乎不用太关心
na_position : {‘first', ‘last'}, default ‘last',默认缺失值排在最后面
2. 排序sort_values
构建DataFrame
import pandas as pd
df = pd.DataFrame([['a', 100, 'c'], ['a', 300, 'a'], ['a', 200, 'b'],
['c', 300, 'a'], ['c', 200, 'b'], ['c', 100, 'c'],
['b', 200, 'b'], ['b', 300, 'a'], ['b', 100, 'c']], columns=['X', 'Y', 'Z'])
X Y Z
0 a 100 c
1 a 300 a
2 a 200 b
3 c 300 a
4 c 200 b
5 c 100 c
6 b 200 b
7 b 300 a
8 b 100 c
按照Y, X两列对df进行降序排列
df.sort_values(by=['Y', 'X'], ascending=False, inplace=True) print(df)
X Y Z
3 c 300 a
7 b 300 a
1 a 300 a
4 c 200 b
6 b 200 b
2 a 200 b
5 c 100 c
8 b 100 c
0 a 100 c
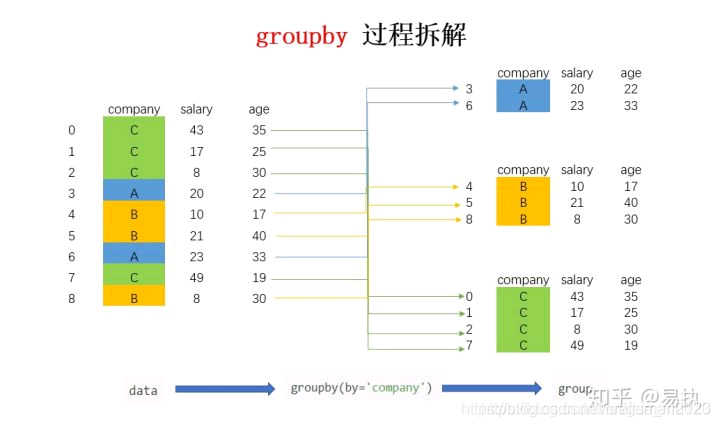
3. 分组排序groupby|sort_values
按照X列进行分组后对Y列进行升序排序
res = df.groupby('X', sort=False).apply(lambda x: x.sort_values('Y', ascending=True)).reset_index(drop=True)
print(res)
X Y Z
0 a 100 c
1 a 200 b
2 a 300 a
3 c 100 c
4 c 200 b
5 c 300 a
6 b 100 c
7 b 200 b
8 b 300 a
示例:
创建数据框
#利用字典dict创建数据框
import numpy as np
import pandas as pd
df=pd.DataFrame({'col1':['A','A','B',np.nan,'D','C'],
'col2':[2,1,9,8,7,7],
'col3':[0,1,9,4,2,8]
})
print(df)
>>>
col1 col2 col3
0 A 2 0
1 A 1 1
2 B 9 9
3 NaN 8 4
4 D 7 2
5 C 7 8
依据第一列排序,并将该列空值放在首位
#依据第一列排序,并将该列空值放在首位 print(df.sort_values(by=['col1'],na_position='first')) >>> col1 col2 col3 3 NaN 8 4 0 A 2 0 1 A 1 1 2 B 9 9 5 C 7 8 4 D 7 2
依据第二、三列,数值降序排序
#依据第二、三列,数值降序排序 print(df.sort_values(by=['col2','col3'],ascending=False)) >>> col1 col2 col3 2 B 9 9 3 NaN 8 4 5 C 7 8 4 D 7 2 0 A 2 0 1 A 1 1
根据第一列中数值排序,按降序排列,并替换原数据
#根据第一列中数值排序,按降序排列,并替换原数据
df.sort_values(by=['col1'],ascending=False,inplace=True,
na_position='first')
print(df)
>>>
col1 col2 col3
3 NaN 8 4
4 D 7 2
5 C 7 8
2 B 9 9
1 A 1 1
0 A 2 0
按照索引值为0的行,即第一行的值来降序排序
x = pd.DataFrame({'x1':[1,2,2,3],'x2':[4,3,2,1],'x3':[3,2,4,1]})
print(x)
#按照索引值为0的行,即第一行的值来降序排序
print(x.sort_values(by =0,ascending=False,axis=1))
>>>
x1 x2 x3
0 1 4 3
1 2 3 2
2 2 2 4
3 3 1 1
x2 x3 x1
0 4 3 1
1 3 2 2
2 2 4 2
3 1 1 3
到此这篇关于pandas中DataFrame排序及分组排序的文章就介绍到这了,更多相关pandas 排序及分组排序内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:
- Pandas之排序函数sort_values()的实现
- Python数据分析Pandas Dataframe排序操作
- 使用Pandas对数据进行筛选和排序的实现
- Pandas分组与排序的实现
- pandas通过索引进行排序的示例
- pandas多级分组实现排序的方法
- pandas的排序和排名的具体使用
- 浅谈Pandas 排序之后索引的问题
- Pandas数值排序 sort_values()的使用
本文由 华域联盟 原创撰写:华域联盟 » pandas中DataFrame排序及分组排序的实现示例
转载请保留出处和原文链接:https://www.cnhackhy.com/160447.htm